

Citizen Data Scientist is a relatively new term, used for people using latest advanced capabilities to general ML models, but are not from a core Data Science or Statistics background.
In heading here, have specifically used a prefix ‘Academic’, reasons being:
- One or single time Analytics only >A single table non-complex dataset
- Standard process followed
Also to set context, a bit about Automated Machine Learning (Auto ML), specific the one developed by SalesForce here. Its important to note here that even in R/ Python, we do have now open source AutoML libraries available; but again they do require substantial coding knowledge & efforts to utilize and finally deploy.
About Data & Business Problem:
Company: Mobile Network provider, Dataset: Customer details/ consumption, Business Problem: Customer Attrition

Steps followed in an Academic Process:
- Data Exploration & Visualization
- Data Preparing (Training & Testing datasets)
- Initial model (M1) building with all variables includes
- Model M1: Variables importance & Model performance analysis
- Model refining (M2, M3,..): By changing hyperparameters, Variables selection
- Models (M1, M2, ..): Performance Comparison & final model selection
- Final selected Model: Communicating Results
Data Exploration & Visualization:
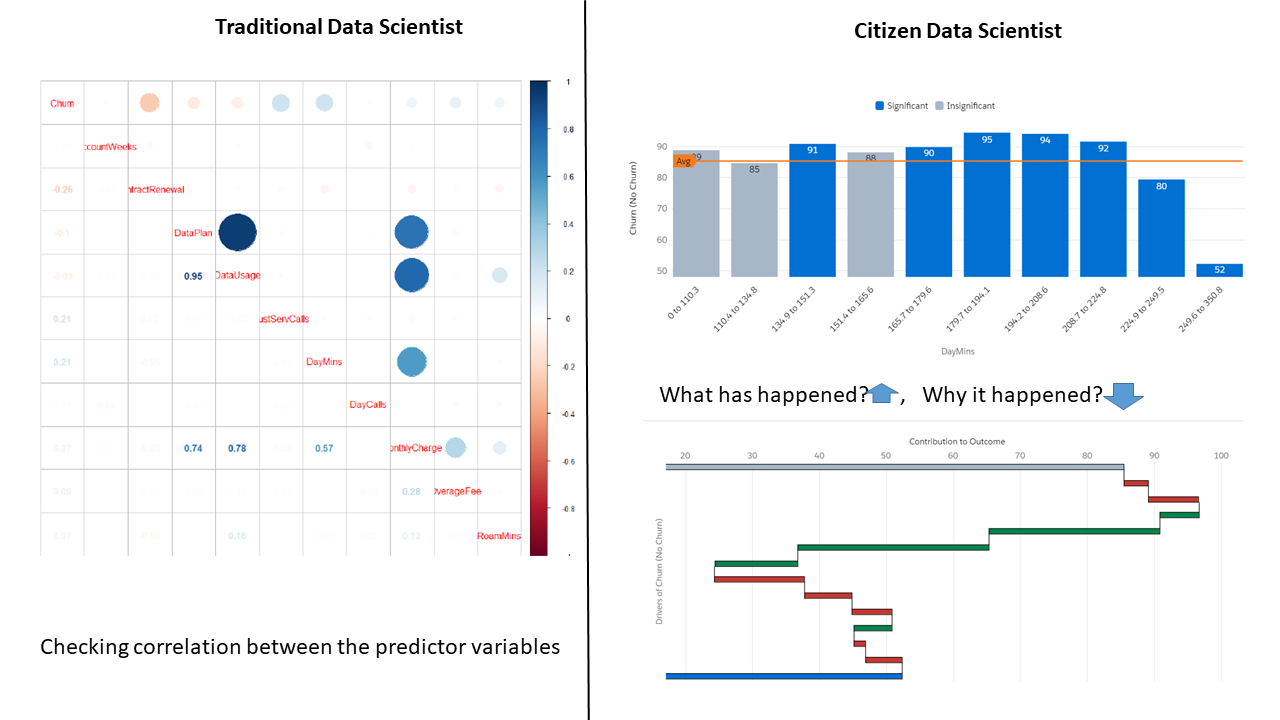
Data Preparation (Division):
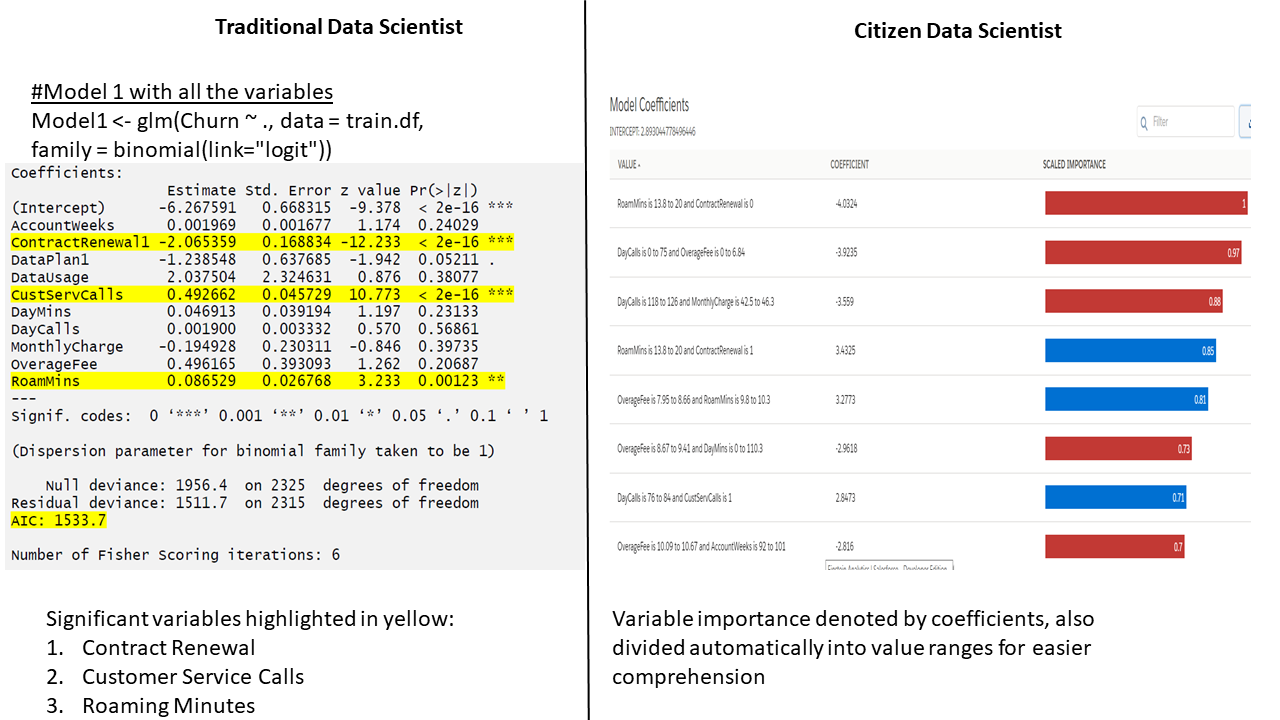
Initial Model Building, with all variables available:
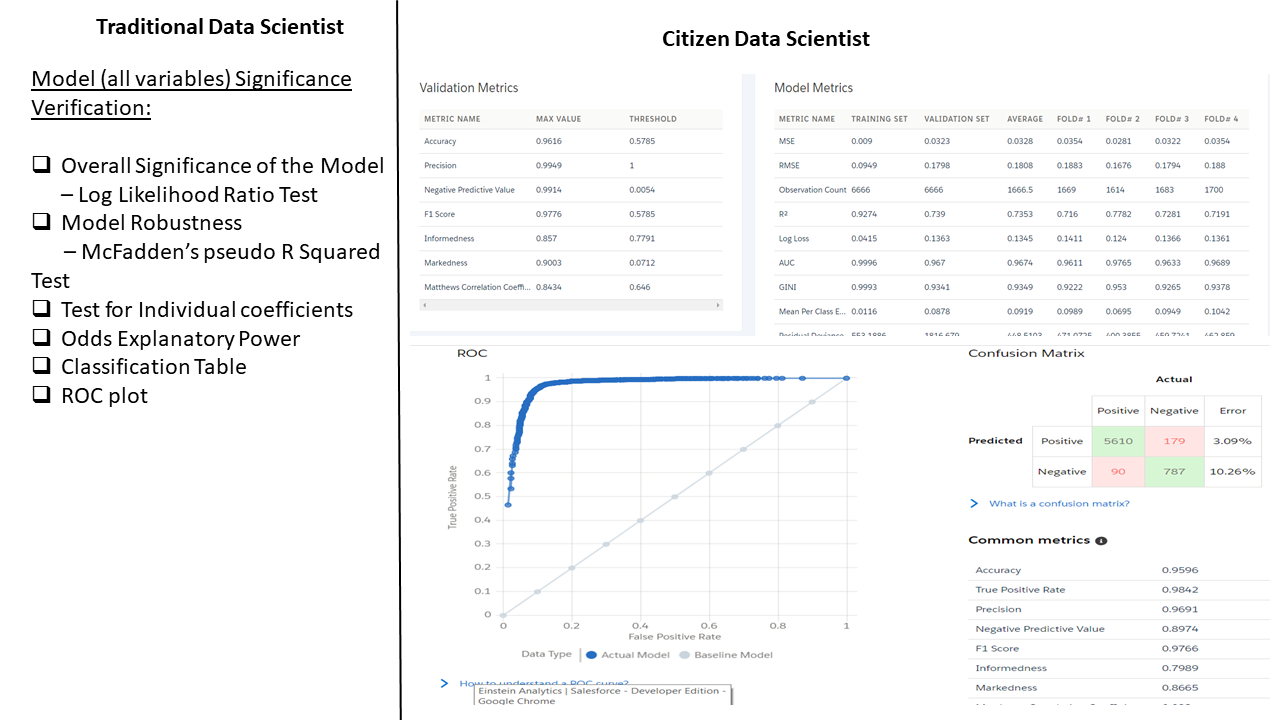
Model Refining:

Models Comparison:
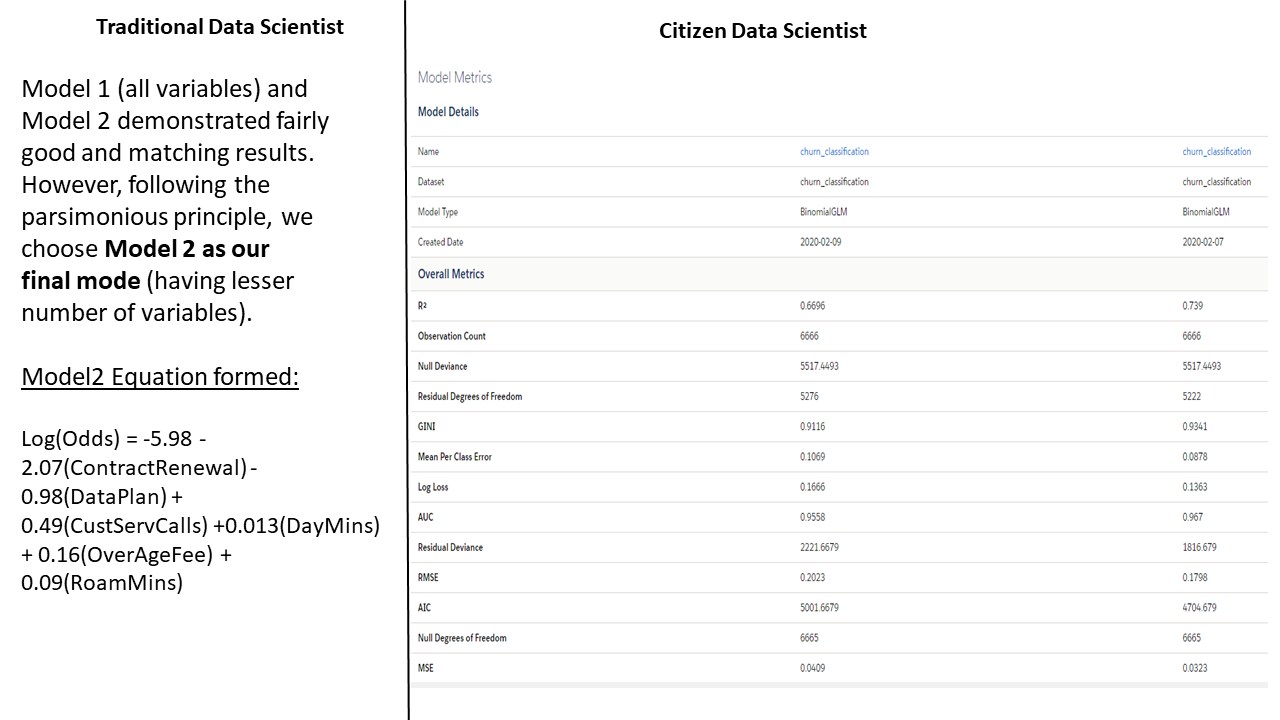
Final Interpretatio:
Final Thoughts…
Modelling by the Einstein Discovery is coding-free, highly time-saving & intuitive for non-Data Science experts also.
However, this does not rule out importance of Domain knowledge & interpreting results of a ML model statistically.







